Ievads
Mūsdienās visi runā par mākslīgo intelektu kā par universālu rīku, kas spēj atrisināt jebkuru problēmu. Tomēr realitātē šie AI modeļi bieži vien darbojas kā “melnā kaste” 📦 – rezultāti var būt neprognozējami, un atbilde var atšķirties pat tad, ja jautājums tiek uzdots identiski. Tas biznesā rada riskus.
Tieši tāpēc klasiskā mašīnmācīšanās (Machine Learning) joprojām ir neaizvietojama un kritiski svarīga. Tā balstās uz matemātisku precizitāti un tiek izmantota daudzās nozarēs, lai pieņemtu izšķirošus lēmumus:
- 🏦 Banku sektorā: Kredītu atmaksas risku izvērtēšanai.
- 🛡️ Apdrošināšanā: Krāpniecības gadījumu atklāšanai un risku precīzai novērtēšanai.
- 🏥 Medicīnā: Slimību diagnostikai un ārstēšanas plānošanai.
- 🛒 Mazumtirdzniecībā: Pieprasījuma un krājumu prognozēšanai.
- 🏃 Fitnesa nozarē: Lietotāju aktivitātes analīzei un ieņēmumu prognozi, ņemot vērā sezonalitāti.
- Google: Iekšējās lietojumprogrammas – Google izmanto mašīnmācīšanos daudzos savos pakalpojumos, piemēram, Google Photos fotoattēlu kategorizēšanai 📸, kā arī tādās funkcijās kā Google Maps ceļojuma laika prognozēšanai 🗺️ un teikumu automātiskai pabeigšanai ✍️.
- Meta: Reklāmu mērķauditorijas atlasei un satura ieteikumiem.
- LinkedIn: Lai ieteiktu jums piemērotākās darba vakances un kontaktus.
Šajā rakstā es parādīšu savu praktisku piemēru no finanšu pasaules: kā var izmantot Python, LightGBM un Optuna, lai izveidotu stabilu modeli, kas ar 92% precizitāti (AUC) prognozē kredītu atmaksu, pārvēršot datus reālā biznesa vērtībā. 👇
🔍 1. Solis: Datu izpēte (EDA) – Datu stāsts
Pirms mēs varam kaut ko prognozēt, mums ir “jāsadzird”, ko dati mums stāsta. Šajā projektā es veicu dziļu izpēti 5 posmos, lai atrastu slēptās likumsakarības.
1.1. Datu struktūra un kvalitāte
Manā rīcībā bija ~600 000 ierakstu. Pirmais pārsteigums? Datu kvalitāte. Izmantojot df.info() un df.isnull().sum(), tika atklājts, ka datu kopā nav nevienas trūkstošas vērtības. Tas ir rets gadījums, kas ļāva mums izlaist sarežģīto datu aizpildīšanas (imputation) posmu un fokusēties uz analīzi.
☑️ Train - Data Info
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 593994 entries, 0 to 593993
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 593994 non-null int64
1 annual_income 593994 non-null float64
2 debt_to_income_ratio 593994 non-null float64
3 credit_score 593994 non-null int64
4 loan_amount 593994 non-null float64
5 interest_rate 593994 non-null float64
6 gender 593994 non-null object
7 marital_status 593994 non-null object
8 education_level 593994 non-null object
9 employment_status 593994 non-null object
10 loan_purpose 593994 non-null object
11 grade_subgrade 593994 non-null object
12 loan_paid_back 593994 non-null float64
dtypes: float64(5), int64(2), object(6)
memory usage: 58.9+ MB1.2. Mērķa mainīgais (Target Variable)
Es sāku ar galveno jautājumu: cik daudzi cilvēki tiešām atmaksā kredītus? Tika atklāts mērens disbalanss:
- ✅ 80% atmaksā kredītu.
- ❌ 20% neatmaksā (default).
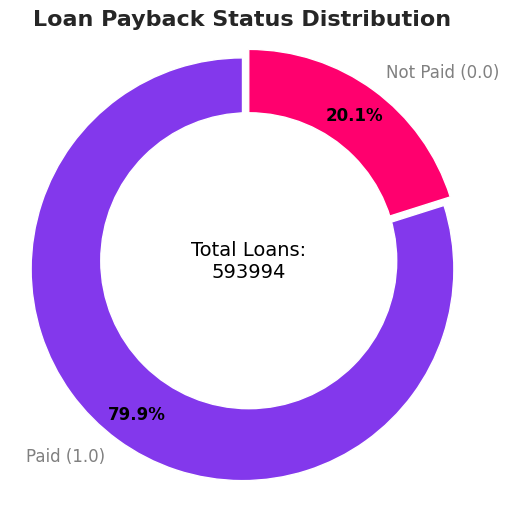
Tas nozīmē, ka mums jābūt uzmanīgiem – ja modelis vienkārši minētu “Visi atmaksās”, tā precizitāte būtu 80%, bet tas būtu bezjēdzīgs. Tāpēc tika izvēlēta AUC-ROC metrika un stratificētā validācija.
count_paid = train_df['loan_paid_back'].value_counts().get(1.0, 0)
count_not_paid = train_df['loan_paid_back'].value_counts().get(0.0, 0)1.3. Skaitlisko pazīmju analīze
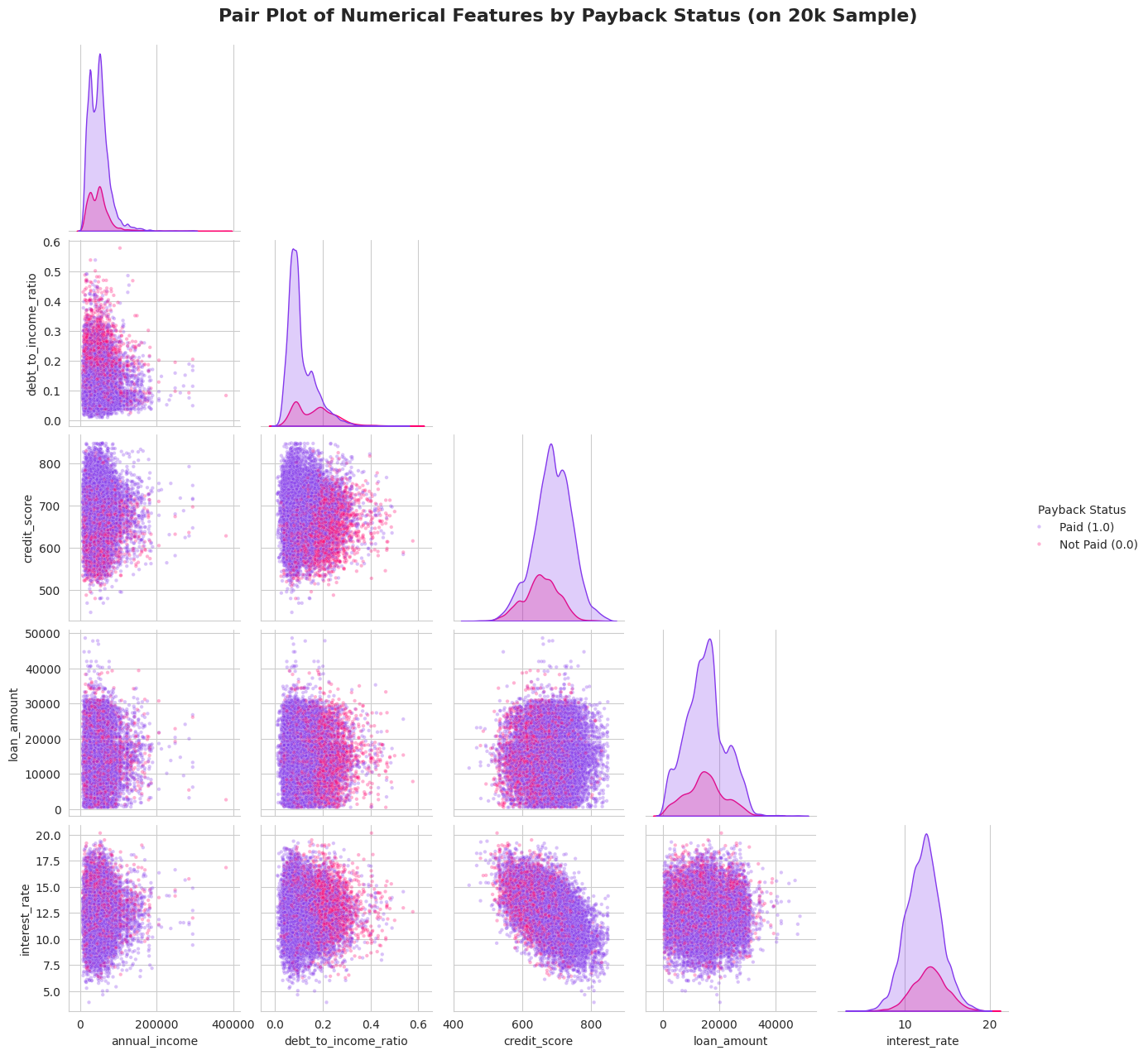
Tālāk es pētīju tādus rādītājus kā Gada ienākumi, Parāda-ienākumu attiecība (DTI) un Kredītreitings. Vizuālā analīze (histogrammas un “box plots”) atklāja divas būtiskas lietas:
- Izteikta nobīde (Skewness): Ienākumi un DTI rādītāji bija spēcīgi nobīdīti pa labi (right-skewed). Vēlāk es to laboju ar
log1ptransformāciju. - Spēcīgi signāli: Bija skaidri redzama atšķirība – cilvēkiem, kas neatmaksā kredītus (sarkanie grafikos), parasti ir zemāks kredītreitings un augstāka parāda slodze.
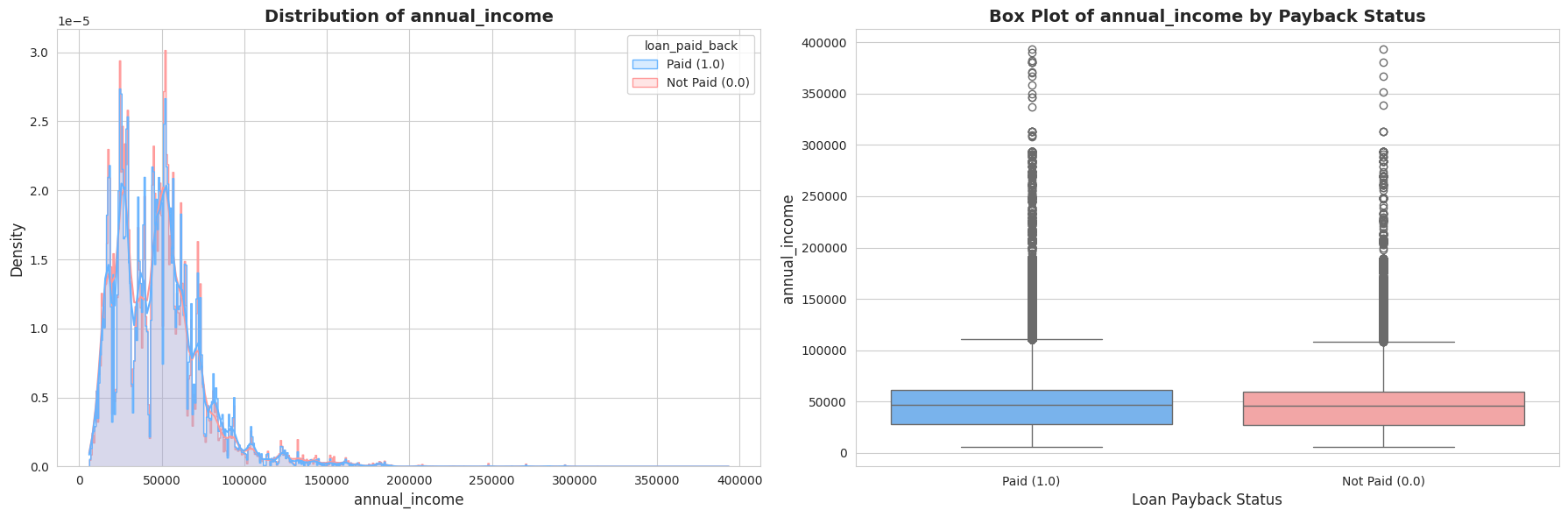
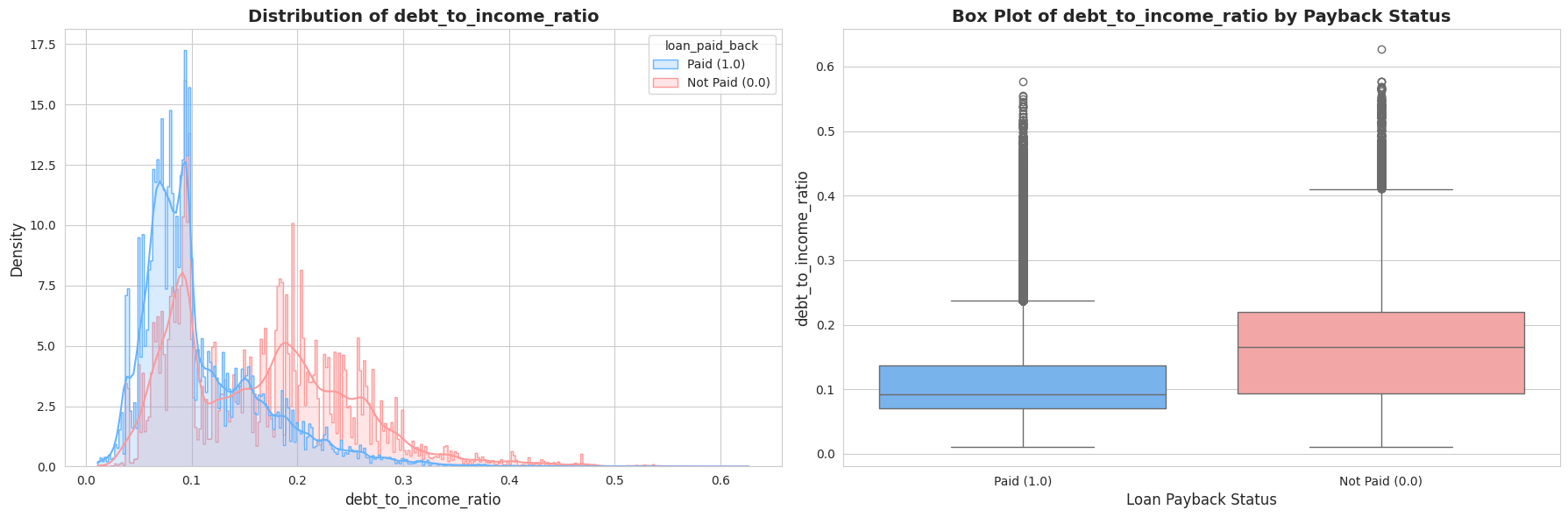
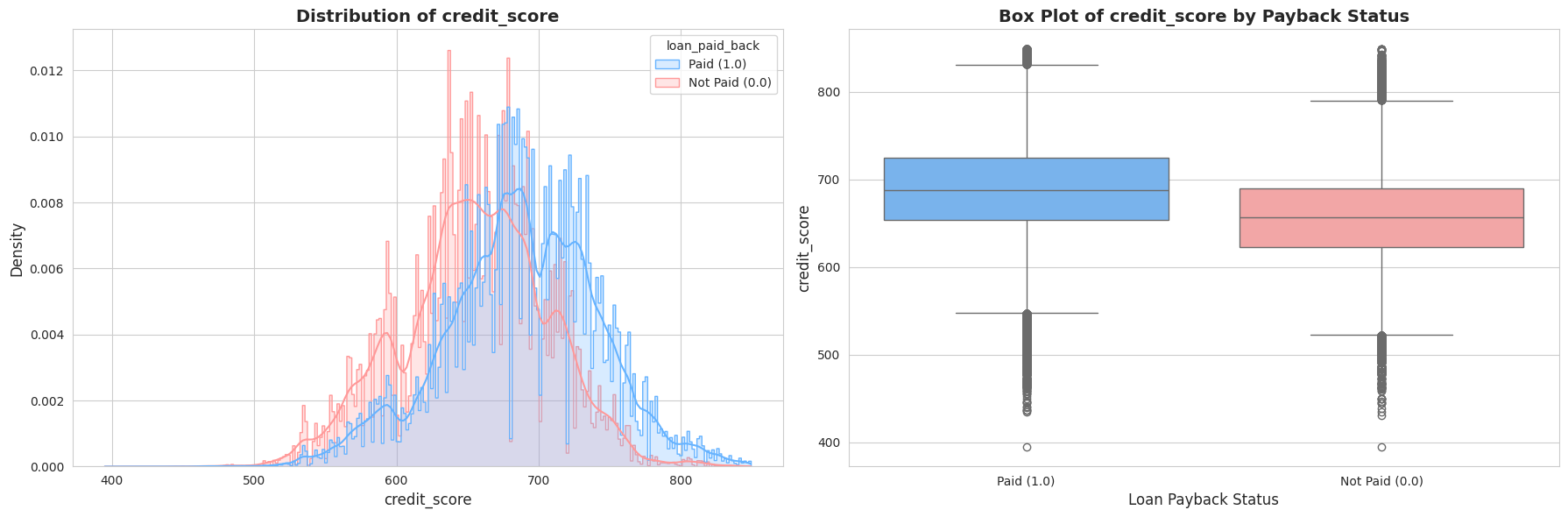
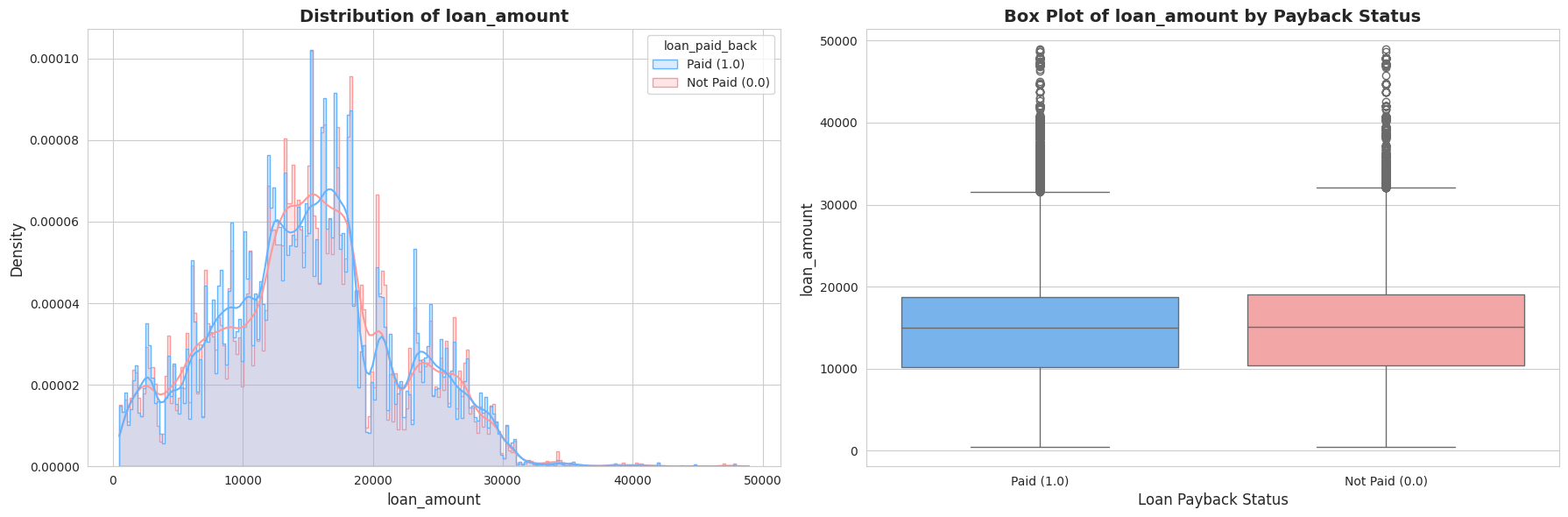
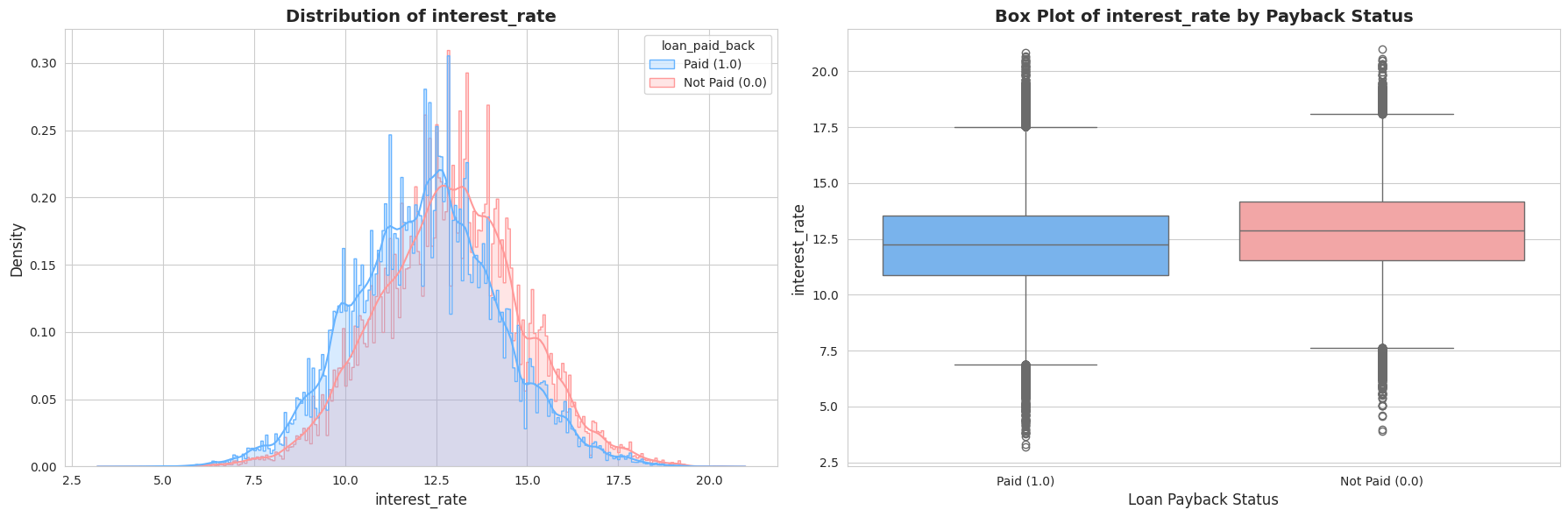
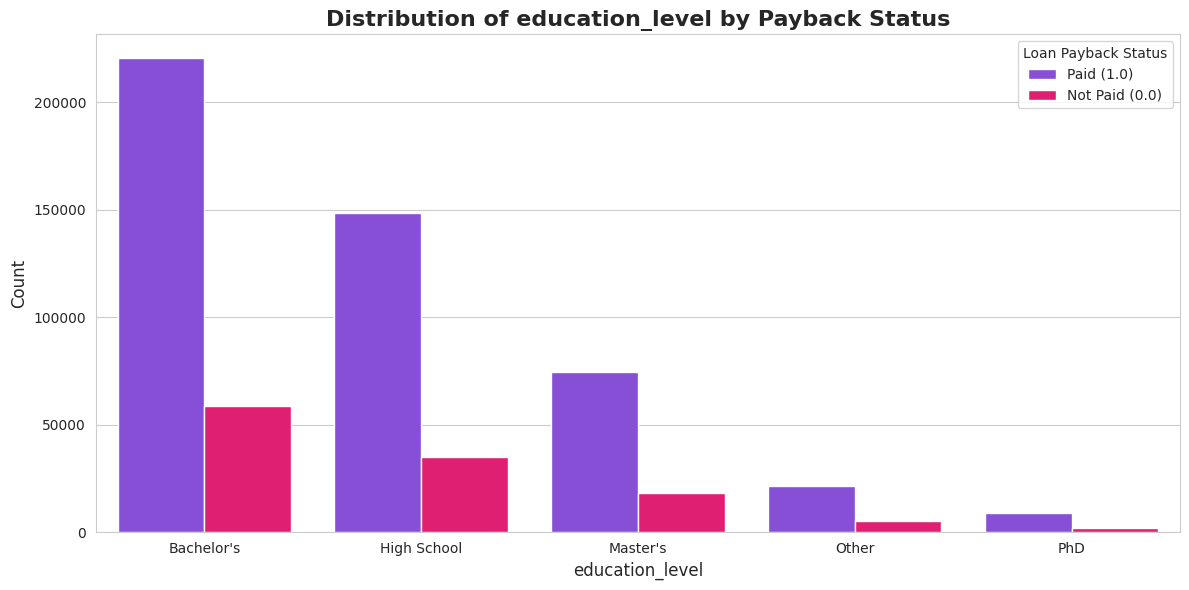
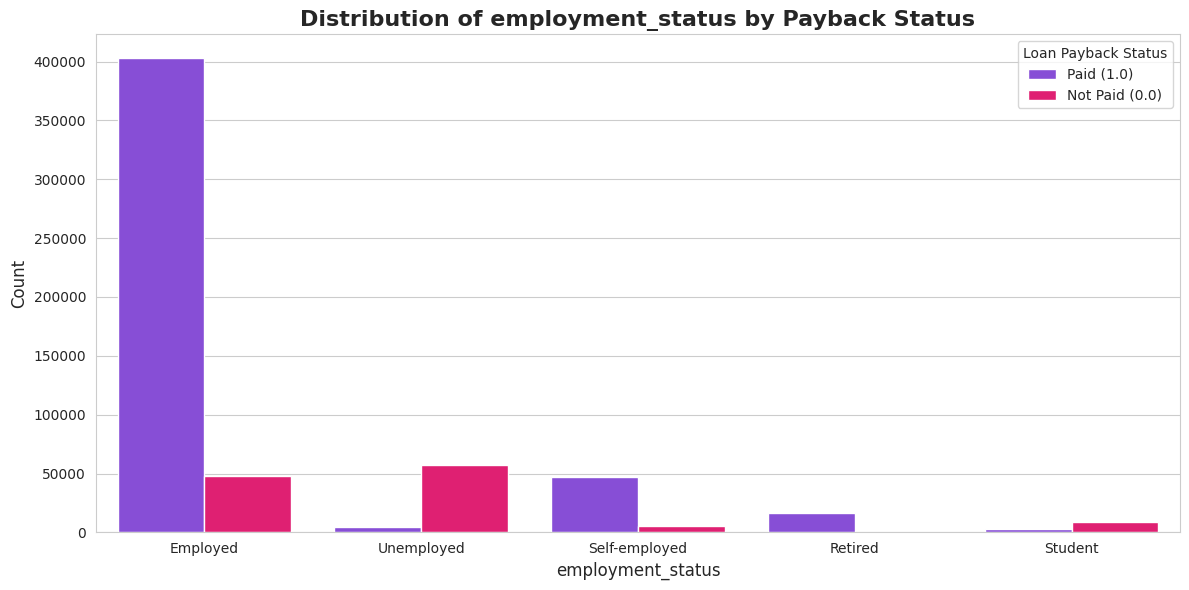
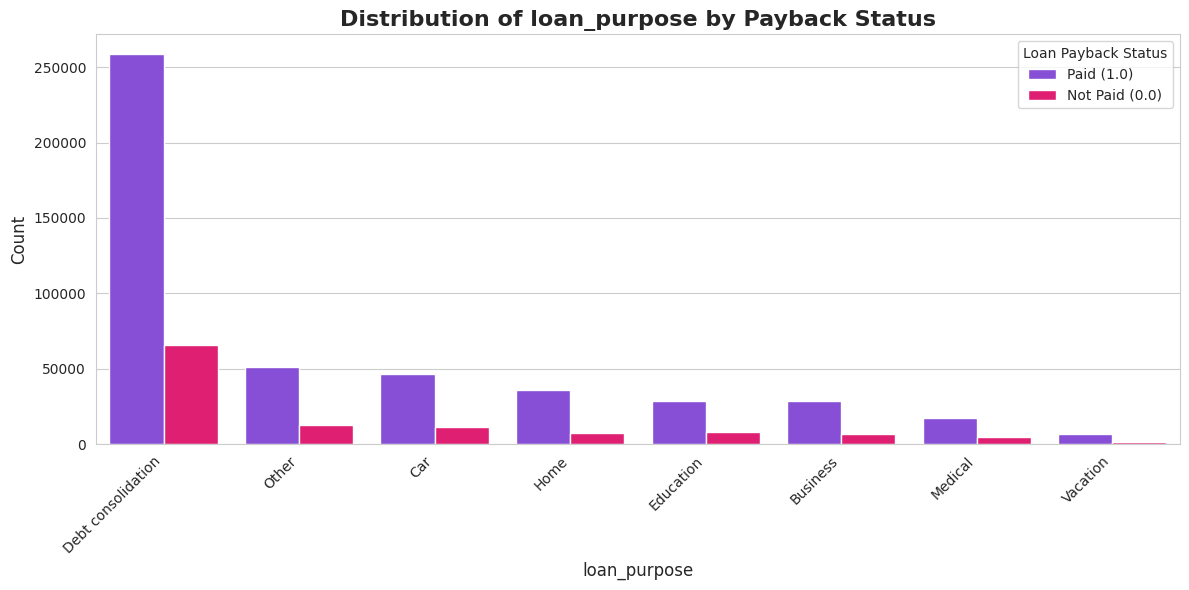
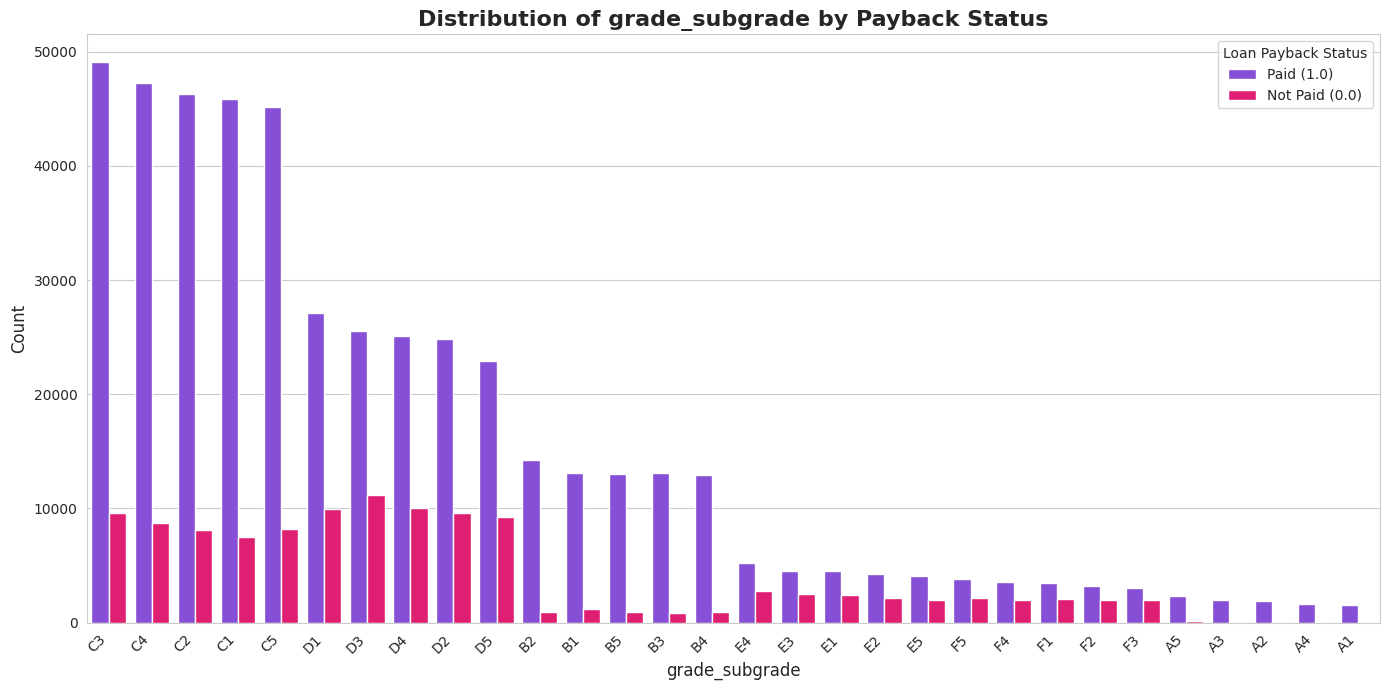
1.4. Kategorisko pazīmju analīze
Šis bija viens no interesantākajiem posmiem. Es analizēju, kā atmaksas varbūtība mainās atkarībā no profesijas vai kredīta mērķa. Atklājums bija dramatisks, bet pašsaprotams:
- 🎓 Studenti un Bezdarbnieki: Ļoti augsts risks (tikai ~7-26% atmaksas rādītājs).
- 👔 Pensionāri un Nodarbinātie: Ļoti zems risks (~90-99% atmaksas rādītājs).
- 🔤 Grade (Kredīta reitings): Perfekta lineāra sakarība – jo zemāka bankas piešķirtā klase (no A uz F), jo mazāka iespēja, ka kredīts tiks atmaksāts.
Šie ieskati man vēlāk ļāva izveidot spēcīgas funkcijas (features).
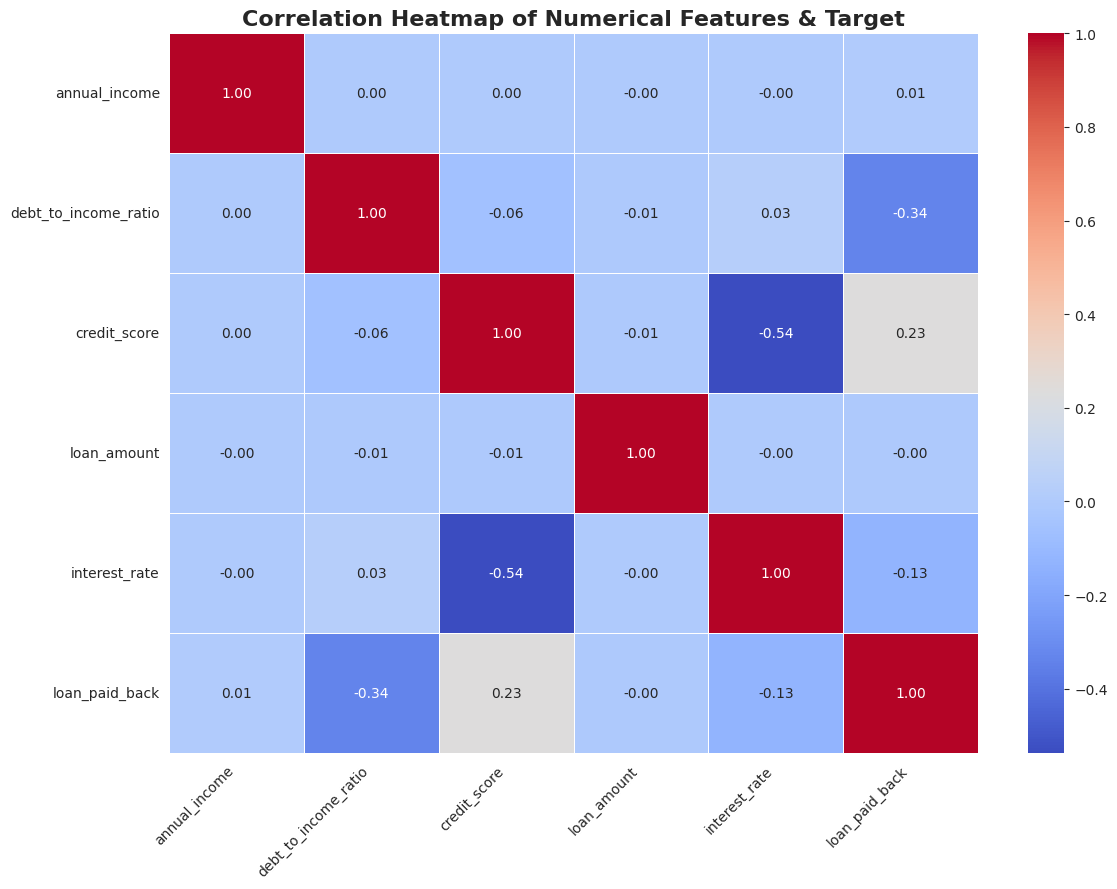
1.5. Korelāciju un Mijiedarbību analīze
Visbeidzot, es pārbaudīju, kā mainīgie ir saistīti savā starpā. Tika izveidots “Pair Plot” un korelācijas matrica, kas parādīja loģisku, bet svarīgu sakarību: Zems kredītreitings = Augstāka procentu likme.
Bija skaidri redzams, ka riskantākie klienti grupējas konkrētos datu apgabalos (zems reitings + augsts DTI), kas man deva ideju izveidot jaunas “kombinētās” funkcijas nākamajā solī.
🧩 2. Solis: Funkciju inženierija (Feature Engineering) – Modeļa “degviela”
Neapstrādāti dati reti ir pietiekami, lai sasniegtu izcilus rezultātus. Funkciju inženierija ir process, kurā mēs izmantojam savas zināšanas par nozari (šajā gadījumā – finansēm), lai izveidotu jaunus, spēcīgus mainīgos. Šeit ir mana stratēģija:
2.1. Trokšņa novēršana
Pirmais solis bija vienkāršs, bet efektīvs: tika izdzēsti gender (dzimums) un marital_status (ģimenes stāvoklis). Mans EDA pierādīja, ka šiem datiem nav nekādas saistības ar kredīta atmaksu. Mazāk “trokšņa” nozīmē stabilāku modeli.
2.2. “Gudrā” kodēšana (Smart Encoding)
Datos bija kolonna grade_subgrade (piem., “C3”), kas bija ļoti svarīga, bet teksta formātā modelis to nesaprot. Tā vietā, lai izmantotu standarta “One-Hot” kodēšanu (kas radītu 35 jaunas kolonnas), mēs izmantojām kārtas kodēšanu (Ordinal Encoding):
- Burtu (A-F) pārvērtu ciparā (A=1, B=2…).
- Apvienoju to ar apakšklasi (3), iegūstot jaunu skaitlisku vērtību grade_combined (piem., C3 -> 33).
Rezultāts: Modelis uzreiz “saprot”, ka C3 ir riskantāks par A1, bet drošāks par F5.
2.3. Finanšu rādītāju izveide (Domain Knowledge)
Šis bija interesants instruments. Es izveidoju jaunas pazīmes, balstoties uz banku loģiku:
- 💰 loan_to_income: Kredīta summa dalīta ar gada ienākumiem. Vai aizņēmums ir samērīgs ar algu?
- 📉 total_debt: Gada ienākumi reizināti ar DTI (Parāda-ienākumu attiecību). Tas parāda kopējo parādu apjomu dolāros.
- 🏠 available_income: Cik naudas klientam paliek pāri pēc parādu nomaksas?
- ⚖️ affordability: Vai brīvie līdzekļi sedz ikmēneša maksājumu?
2.4. Matemātiskās transformācijas
Tā kā ienākumu dati bija ļoti nevienmērīgi (ar dažiem miljonāriem, kas kropļo vidējos rādītājus), es izmantoju Logaritmisko transformāciju (np.log1p). Tas padarīja datu sadalījumu “normālāku” un vieglāk uztveramu modelim.
💻 Koda ieskats: Pazīmju izveides funkcija
def create_features(df):
# Pārvēršam reitingus skaitļos (A->1, B->2...)
grade_map = {'A': 1, 'B': 2, 'C': 3, 'D': 4, 'E': 5, 'F': 6, 'G': 7}
df['grade_rank'] = df['grade_subgrade'].str[0].map(grade_map)
# Izveidojam finanšu attiecības
df['loan_to_income'] = df['loan_amount'] / (df['annual_income'] + 1)
df['total_debt'] = df['debt_to_income_ratio'] * df['annual_income']
df['available_income'] = df['annual_income'] - df['total_debt']
# Logaritmiskā transformācija nobīdītiem datiem
df['log_annual_income'] = np.log1p(df['annual_income'])
return df💻 Transformēto datu informācija
📊 New Train Data Info
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 593994 entries, 0 to 593993
Data columns (total 26 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 593994 non-null int64
1 annual_income 593994 non-null float64
2 debt_to_income_ratio 593994 non-null float64
3 credit_score 593994 non-null int64
4 loan_amount 593994 non-null float64
5 interest_rate 593994 non-null float64
6 education_level 593994 non-null object
7 employment_status 593994 non-null object
8 loan_purpose 593994 non-null object
9 loan_paid_back 593994 non-null float64
10 grade_rank 593994 non-null int64
11 grade_number 593994 non-null int64
12 grade_combined 593994 non-null int64
13 loan_to_income 593994 non-null float64
14 total_debt 593994 non-null float64
15 available_income 593994 non-null float64
16 monthly_payment 593994 non-null float64
17 payment_to_income 593994 non-null float64
18 affordability 593994 non-null float64
19 credit_interest 593994 non-null float64
20 income_credit 593994 non-null float64
21 log_annual_income 593994 non-null float64
22 log_loan_to_income 593994 non-null float64
23 log_total_debt 593994 non-null float64
24 log_available_income 593994 non-null float64
25 log_monthly_payment 593994 non-null float64
dtypes: float64(18), int64(5), object(3)
memory usage: 117.8+ MB🤖 3. Solis: Modelēšana un Optimizācija – No minējumiem līdz precizitātei
Datu zinātnē modeļa palaišana (model.fit) ir vienkāršākā daļa. Māksla slēpjas validācijas stratēģijā un optimizācijā. Mēs nepaļāvāmies uz veiksmi – mēs izmantojām sistemātisku pieeju.
3.1. Aizsardzība pret pārmācīšanos (Overfitting)
Tā vietā, lai sadalītu datus vienkāršā 80/20 proporcijā (kas ir riskanti, jo rezultāts ir atkarīgs no tā, kuri dati trāpās testā), es izmantoju 10-kāršu Stratificēto Validāciju (10-Fold Stratified Cross-Validation).
- Kā tas strādā: Dati tiek sadalīti 10 daļās, saglabājot 80:20 mērķa attiecību katrā daļā.
- Rezultāts: Mēs iegūstam 10 dažādus modeļus un vienu, statistiski ticamu OOF (Out-of-Fold) rezultātu. Mans gala iesniegums (submission) bija visu 10 modeļu prognožu vidējais rādītājs, kas ir daudz stabilāks nekā viena modeļa minējums.
3.2. “Lielais Trijnieks”
Es izvēlējos Gradient Boosting algoritmus, kas šobrīd dominē tabulāro datu sacensībās. Es trenēju trīs dažādus modeļus, izmantojot GPU paātrinājumu Kaggle vidē:
- 🚀 LightGBM: Ātrs, efektīvs un manā eksperimentā izrādījās visprecīzākais.
- 🌲 XGBoost: Klasisks, spēcīgs algoritms, kas pievērsa lielāku uzmanību nodarbinātības statusam.
- 🐱 CatBoost: Lieliski tiek galā ar kategorijām un sniedza “hibrīda” skatījumu.
3.3. Hiperparametru optimizācija ar “Optuna”
Es izmantoju Optuna bibliotēku, lai automatizēti atrastu labākās kombinācijas (piem., learning_rate, num_leaves, depth).
- Optuna veica 50 eksperimentus (trials) katram modelim.
- Tas uzlaboja manu LightGBM rezultātu no 0.92225 uz 0.92274. Iespējams, izklausās maz, bet sacensībās un lielos biznesa apjomos šī atšķirība ir būtiska.
3.4. Modeļu apvienošana (Blending)
Beidzot es izmēģināju Modeļu apvienošanu (Blending) – paņēmot vidējo rezultātu no visiem trim modeļiem. Tomēr dati parādīja, ka mans Optimizētais LightGBM viens pats darbojas labāk nekā maisījums. Datu zinātnē ir svarīgi uzticēties validācijas rezultātiem, nevis intuīcijai, tāpēc es izvēlējāmies vienkāršāko un spēcīgāko risinājumu.
💻 Koda ieskats: Optuna optimizācija
import optuna
def objective(trial):
params = {
'learning_rate': trial.suggest_float('learning_rate', 0.01, 0.05),
'num_leaves': trial.suggest_int('num_leaves', 20, 150),
'subsample': trial.suggest_float('subsample', 0.6, 0.95),
'device': 'gpu' # Izmantojam GPU ātrumam
}
model = lgb.LGBMClassifier(**params)
model.fit(X_train, y_train)
return roc_auc_score(y_val, model.predict_proba(X_val)[:, 1])
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=50)💻 Koda ieskats: Finālais LightGBM modelis
import lightgbm as lgb
# 🏆 Labākie parametri, ko atradu ar Optuna
best_params = {
'n_estimators': 5000, # Maksimālais koku skaits
'learning_rate': 0.0327, # Lēna un stabila mācīšanās
'num_leaves': 49, # Koka sarežģītība
'max_depth': 5, # Ierobežots dziļums pret "overfitting"
'subsample': 0.798, # Datu daļa katram kokam
'colsample_bytree': 0.718, # Pazīmju daļa katram kokam
'reg_alpha': 0.086, # L1 Regularizācija
'reg_lambda': 0.083, # L2 Regularizācija
'device': 'gpu', # GPU paātrinājums 🚀
'objective': 'binary',
'metric': 'auc'
}
# Modeļa inicializēšana
model = lgb.LGBMClassifier(**best_params)
# Trenējam ar "Early Stopping" (apstājas, ja 100 soļus nav uzlabojumu)
model.fit(
X_train, y_train,
eval_set=[(X_val, y_val)],
callbacks=[lgb.early_stopping(stopping_rounds=100)]
)📈 4. Solis: Rezultāti un Biznesa Stratēģija – Ko tas nozīmē bankai? 🏦
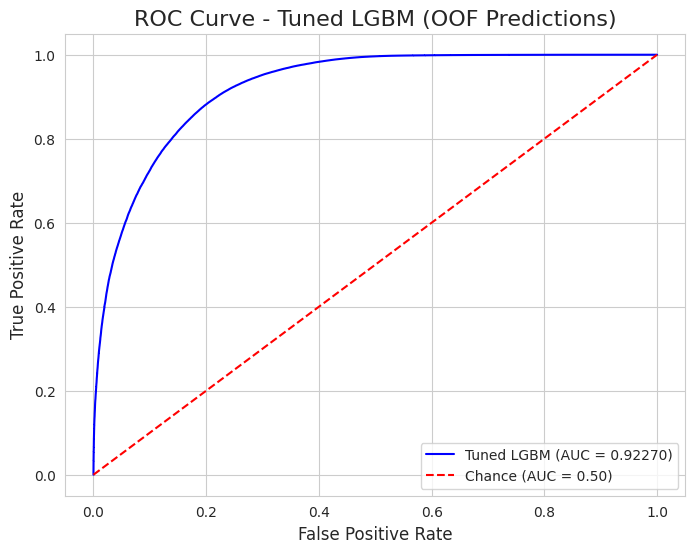
Datu zinātne nebeidzas ar augstu rezultātu – tā beidzas ar lēmumu. Tā kā šis ir klasisks binārās klasifikācijas uzdevums (kur mums jāprognozē viens no diviem iznākumiem: vai klients atmaksās kredītu, vai nē), precizitāte ir izšķiroša. Šis modelis sasniedza AUC 0.9227, kas ir izcils rādītājs šādas sarežģītības problēmai. Bet ko tas reāli dod biznesam? 🤔
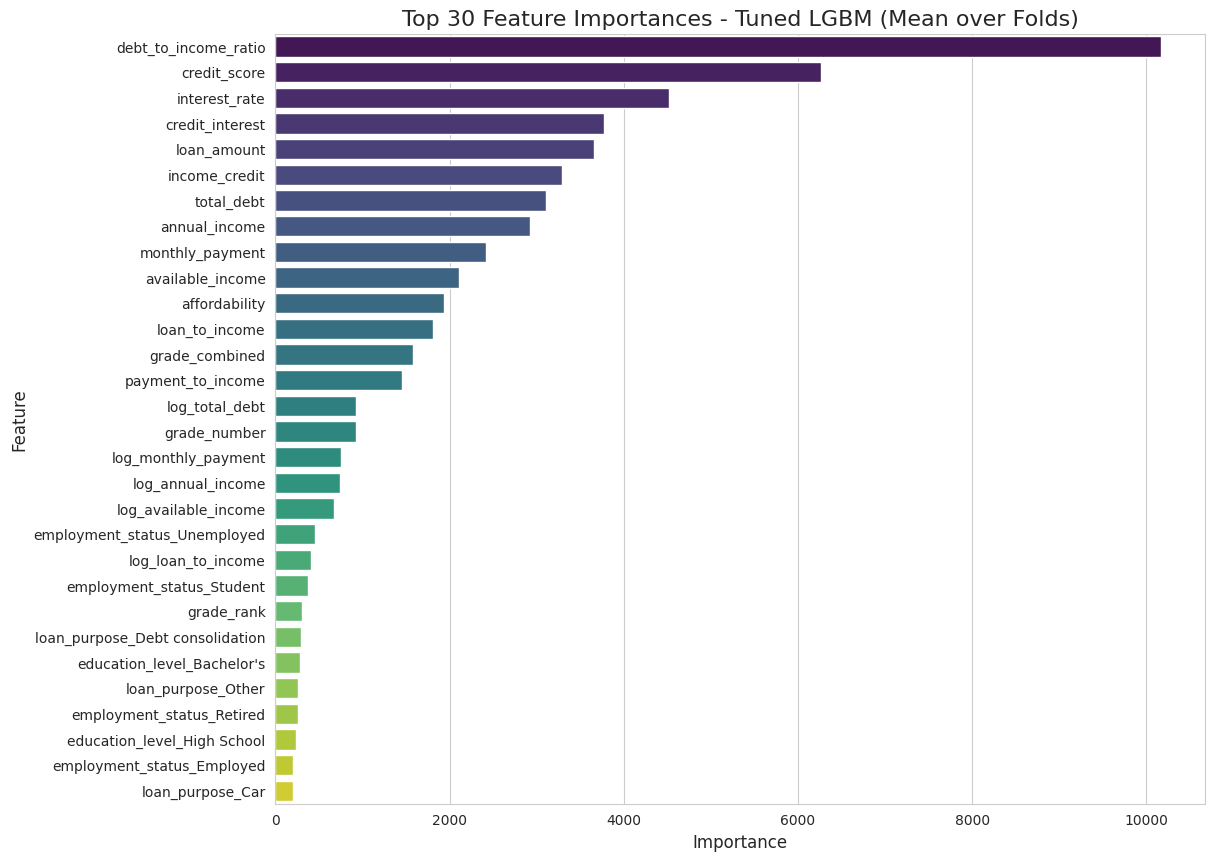
4.1. Modeļa kvalitāte ⭐
ROC līkne pierādīja, ka modelis spēj stabili atšķirt labos klientus no sliktajiem. Aplūkojot Feature Importance, trīs galvenie faktori ir loģiski un pamatoti:
- Debt-to-Income Ratio (DTI) 📉
- Credit Score 🏅
- Interest Rate 📈
4.2. Stratēģiskais lēmums: Ķert “sliktos” kredītus 🎣
Vislielākais izaicinājums ir izvēlēties pareizo “slieksni” (threshold). Standarta pieejā (50% varbūtība) modelis bija pārāk “piesardzīgs” un palaida garām ~40% no sliktajiem kredītiem. Bankai vai citiem aizdevējiem tie ir milzīgi zaudējumi. 💸
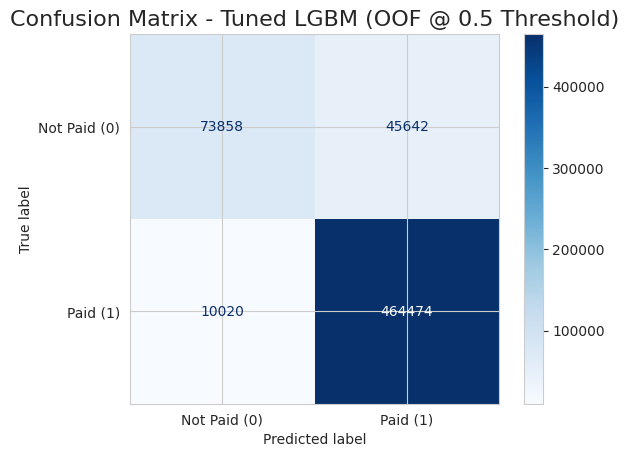
Šādā gadījumā var mainīt biznesa lēmumu un mainīt stratēģiju ♟️. Pazeminot slieksni uz 0.20, padarot modeli stingrāku.
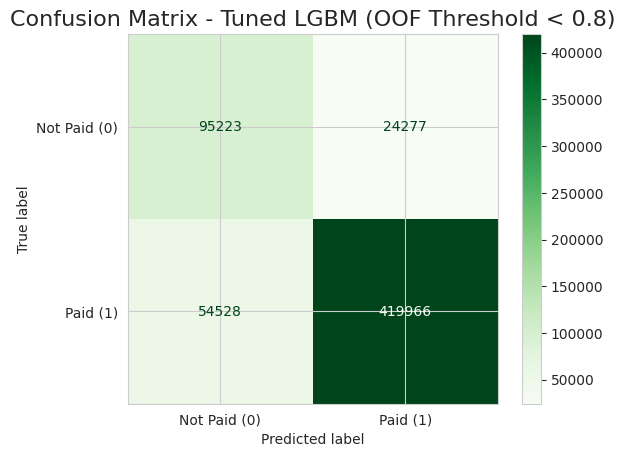
Rezultāts:
- 🔴 Pirms (Threshold 0.5): Modelis atklāja tikai 62% no nemaksātājiem.
- 🟢 Pēc (Threshold 0.2): Modelis veiksmīgi identificēja 80% no visiem nemaksātājiem!
Secinājums: Lai gan tas nozīmē, ka mums manuāli jāpārbauda vairāk pieteikumu, bankai tas ir finansiāli izdevīgāk nekā izsniegt aizdevumus, kas nekad netiks atmaksāti.
Aplūkojot rezultātus, redzams, ka stratēģijas maiņa atmaksājas. ⭐ Mēs veiksmīgi identificējām un apturējām 95 223 sliktos kredītus (True Positives), kas citādi būtu radījuši tiešus finansiālus zaudējumus. Protams, nekas nav perfekts – 24 277 gadījumos (False Negatives) modelis tomēr palaida garām nemaksātājus. 💰
Taču “cena” par šo augsto drošību ir 54 528 labi klienti (False Positives), kurus modelis kļūdaini atzīmēja kā riskantus. 🤔 Šeit sākas “aprēķināta riska vadība”: tā vietā, lai šiem cilvēkiem automātiski atteiktu, banka novirza tos uz manuālo pārbaudi. Kredītspeciālista laiks maksā naudu, taču tas ir nesalīdzināmi lētāk nekā izsniegt miljoniem eiro vērtus “toksiskus” kredītus. ⭐
Tikmēr lielākā daļa – 419 966 uzticami klienti (True Negatives) – saņem ātru, automātisku apstiprinājumu, ļaujot darbiniekiem fokusēties tikai uz sarežģītajiem gadījumiem. 💰
5. Kopsavilkums un Galvenās Atziņas
Šis projekts uzskatāmi parāda, ka veiksmīgs mašīnmācīšanās risinājums nav tikai par koda rakstīšanu vai modeļa precizitātes procentiem (AUC). Tas ir par biznesa problēmu tulkošanu datu valodā.
Mēs redzējām, kā sistemātiska pieeja rada vērtību:
- Dziļa izpēte (EDA) ļāva mums “sadzirdēt”, ko dati stāsta par klientu uzvedību, nevis paļauties uz pieņēmumiem.
- Funkciju inženierija un Optuna palīdzēja izspiest maksimumu no pieejamās informācijas, sasniedzot 92% precizitāti.
- Sliekšņa pielāgošana (Threshold tuning) pierādīja, ka modelis ir elastīgs instruments — mēs varam izvēlēties būt konservatīvi (mazāk riska) vai agresīvi (vairāk klientu), atkarībā no bankas stratēģijas.
Galu galā, šādi modeļi neaizstāj kredītspeciālistus, bet gan dod viņiem “superspējas” — iespēju fokusēties tikai uz svarīgāko, kamēr algoritms paveic melno darbu, izsijājot tūkstošiem pieteikumu sekundes laikā.